
The essence of Sabad (divine Wisdom) is inaccessible to most of the Sikh population. Though a plethora of translations created by esteemed early twentieth-century Sikh scholars are available in Panjabi, as well as more recent English translations, there is renewed interest in methods to illuminate the panorama and magnitude within the Guru Granth Sahib. This project aims to connect contemporary audiences to Sabad within their present social, cultural, and linguistic context, offering a fresh perspective that resonates with their unique contexts.
Towards those ends, developing a meticulously researched resource of the Guru Granth Sahib is imperative, catering to the diverse global Sikh audience while harnessing global collaborations. With this mission in mind, this project endeavors to create an unprecedented comprehensive interpretation and commentary of the Guru Granth Sahib in Panjabi and English. Panjabi serves 80% of today’s Sikh population, while English opens the gateway to Guru Wisdom for nearly 1.5 billion English speakers worldwide. As the world seeks access to Sabad in various languages, they are more likely to use English-based translation tools.
This collaborative effort birthed the development of a platform offering user-friendly online access to the infinite wisdom of the Guru Granth Sahib:
- Search and Navigation: Users can easily search for specific authors, Bani, page number, or keywords within the Guru Granth Sahib. The platform offers advanced search capabilities to help users find relevant results quickly. Additionally, intuitive navigation tools will enable users to browse through annotations easily.
- Grammar and Etymology: Users can access the literal and implied meanings of keywords in Sabad. Our website offers details about the grammatical function of individual words, similar to a standard dictionary. In addition, users can access the etymology of words, allowing them to explore the historical origins and development of the language.
- Literal Translation: This platform offers literal translation of the original text in both Panjabi and English, ensuring accuracy and faithfulness to the original Sabad.
- Interpretive Transcreation: The platform provides an interpretive transcreation of the Sabad, presenting it in contemporary Panjabi and English. This approach involves capturing the essence and meaning of the original teachings while adapting them to resonate with contemporary audiences.
- Commentary and Discourses: Users can access a collection of thoughtful commentaries that provide in-depth reflections on Bani, promoting a deeper understanding of the Guru Granth Sahib.
- Annotations and Explanations: The platform incorporates annotations and explanations to assist users in comprehending the Sabad's context, meanings, and interpretations. These annotations encompass poetical, historical, and musical insights drawn from research conducted by esteemed scholars, theologians, and Sikh experts. By integrating these scholarly perspectives, the platform aims to enhance user's understanding.
- Parallel Panjabi and English: The platform presents annotation on the Guru Granth Sahib in parallel Panjabi and English versions, allowing users to compare and understand the research, translations, and transcreation in both languages on-site. This feature facilitates accessibility and comprehension for a wider audience.
Focusing Global Expertise
The project facilitates global collaboration for the annotation and exegesis of the Guru Granth Sahib. Hence, it involves actively engaging a dedicated team of subject-matter experts (SMEs) contributing their expertise and curating research, ensuring Sabad's comprehensive and thoughtful exploration.
Rather than a linear approach of working through the Guru Granth Sahib from cover to cover, the project embraces the tradition of organizing research by Bani (compositions). Version 1 was driven by the particular emphasis on the Banis attributed to Guru Nanak Sahib. The project now extends its focus to encompass the Banis contributed by others within the Guru Granth Sahib. Currently, all annotations on Banis revealed by Guru Ramdas Sahib have been published.
A significant portion of our work involves the meticulous annotation of the Guru Granth Sahib in the Gurmukhi script, serving as the driving force behind the transcreation efforts in both Panjabi and English. Linguistically, we thoroughly examine each word, delving into its meaning, grammar, and etymology. Subsequently, we develop the meaning for each pauri (stanza), encompassing both the literal translation and interpretive transcreation. This comprehensive approach ensures that every element is contextualized, fostering a deeper understanding and interpretation.
Central to our endeavor is the emphasis on curating a rich array of diverse schools of thought and interpretations. By acknowledging and discussing areas of divergence, we lay the foundation for crafting a truly meaningful commentary. Version 1 of our deliveries encompasses historical, musical, and poetical dimensions, while future iterations will venture into other realms, including philosophy, governance, cosmic insights, environment, interfaith, and more.
Our project is dedicated to creating an expansive online repository of content freely accessible to a global audience. The convergence of research, interpretation, and technology unlocks the gateway to universal accessibility for the Guru Granth Sahib. This collaboration enables us to dismantle both systemic and language barriers, ensuring that the teachings of the Guru are accessible to all. This digital platform allows individuals worldwide to engage with the impactful teachings of the Guru Granth Sahib, fostering a spirit of inclusivity, knowledge-sharing, and enlightenment.
Translating Texts
Our researchers consider a minimum of three different layers of meaning in translating texts:
- Words and Terms: All words encompass multileveled meanings, connotations, and implications that cannot fully be translated into another language. When a word is used, it carries layers of historical development, contextual specificities, and veiled associations that are often unconsciously present even to the original verbalizer.
- The Historical Development and Implications: When it comes to ideas, similar to individual words, different terms that appear to be nearly equivalent carry distinct implications and connotations. For instance, when referring to the Guru Granth Sahib, using the terms "scripture" or "canon" immediately introduces ideas, connotations, and implications that stem from their usage and development in the English language, some of which carry Judeo-Christian undertones that are not applicable in the Sikh context. Similarly, applying the terms "ved" or "shastra" (Hindu texts) to the Guru Granth Sahib is equally unsuitable, as they bear Dharmic-Hindu connotations derived from the Indological contexts of "shruti" (heard) or "smriti" (memorized).
- The Audience(s): Researchers consider how much prior knowledge users of our website may be assumed to have. The aim can be either to achieve a strict, literal translation to maintain faithfulness to the text or to prioritize a translation that reads smoothly and meaningfully in the host language. Research also considers the extent of additional information required to make the English rendering intelligible and cohesive. Given that this project targets a global audience, both contextualization and clarification are provided to assist readers without prior knowledge, aiming to enhance their understanding and engagement.
The ideal methodology involves considering various factors, including consistency with previous choices in translating these or similar terms, maintaining a balance between literal translations and interpretive transcreations for English comprehension, determining the necessary explanatory footnotes, understanding the preferences and expectations of the audience, and so forth.
It is important to note that since there is no direct one-to-one correspondence between words in different languages, a rigid translation methodology can lead to misrepresentation where contextual considerations are overlooked. Hence, strict adherence to a “consistent” translation is inadvisable. This does not necessarily imply advocating for arbitrary or blatant inconsistencies. A reasoned level of consistency is a laudable goal, with the caveat that translators must be open to possible contextual exceptions.
Features
| WORD | DEFINITION |
|---|---|
| Overview | Provides a brief glimpse into the larger message of a particular stanza, Sabad or Bani. |
| Introduction | This feature provides background information on the Sabad, such as page number, rag, author(s), scholarly arguments, and themes, by drawing in outside sources when necessary. |
| Commentary | Commentaries thoroughly explore the essence of each Sabad, its contemporary applications, subtle nuances, and its departure from its time's prevailing religious or political ideologies. Commentaries encourage global readers to seek more profound engagement with Bani through exposition and meaningful contextualization of the message of the Guru Granth Sahib. |
| Interpretive Transcreation | Provides an interpretive explanation of the original text from the Guru Granth Sahib in modern Panjabi and English. This does not attempt to match its Panjabi counterpart or to map onto the original text. It does not require parentheses as it is not a translation. Instead, it serves to elaborate, contextualize, and expound on the original text and its literal translation for better understanding. |
| Literal Translation (italics) | Provides the literal translation of the original text from the Guru Granth Sahib in which all words, meanings, grammatical positions, and contexts available in the source text have been retained. English, as the target language, lacks the same orality roots as the languages used in the Guru Granth Sahib. Consequently, preserving the structural form and aural tonality of these languages when translating into English poses challenges. To bridge this linguistic gap while upholding poetic balance and beauty, additional words are occasionally included within parentheses in the English italics. This is done to enhance readability, clarity, and maintain poetic equilibrium. In certain instances, sentence structures may also be rearranged to improve comprehension and readability. |
| Meaning | Lists all possible sets of literal meanings and the implied meaning of the given word in the original text. Literal sets of meanings are separated from each other with a comma (,) and separated from an implied set of meanings with a semicolon (;). |
| Grammar | Lists all the grammatical aspects/functions of the word in the original text. Words are categorized based on the following aspects:
|
| Etymology | Presents various forms of words and their potential meanings in different languages. Researchers strive to provide the etymology of each word, often tracing it back to Old Panjabi, Lehndi, Braj, Sindhi, Apbhransh, Prakrit, Pali, Sanskrit, and other sources. While Sanskrit and Arabic/Persian words are written in both Gurmukhi and their respective scripts, words from other languages are only written in Gurmukhi. In Sanskrit, the masculine and feminine forms of a verb are identical, but meanings are given in the masculine form to align with prevailing linguistic conventions. Words in the Guru Granth Sahib that have corresponding singular or plural forms in the respective languages are represented in the same forms. For words that do not have direct matches, equivalent forms have been included. The slash (/) is used when multiple variants of a word exist in a language, while a semicolon (;) separates different language forms and indicates changes in word meaning. Quotation marks (“xyz”) are used when citing original text from a source. Generally, etymology and linguistic forms are provided without specific references, but footnotes include source information when necessary. If a word retains the same meaning as in Sanskrit, Pali, Arabic, etc., its meaning in other languages is not given. In cases where more detail is required, footnotes offer additional information on various uses of a particular word in the Guru Granth Sahib. An effort is made to consult both contemporary and historical dictionaries, as well as literary sources, to showcase the linguistic forms of the words. |
| Historical Dimension | Builds the historical context around a given word/line/Sabad. Information about the historical and cultural milieu (social setting and environment), the origin of the sabad, etc., are shared from Sikh traditional sources such as Guru Granth Sahib interpretations, rahitname (lifestyle codes), sakhi (witness-narratives), parchi (Panjabi writing on the life stories of the Gurus, saints, and bhaktas), janamsakhi (birth-narrative), etc. as well as from the contemporary historical and cultural South Asian works. |
| Musical Dimension | Provide information on the literal meaning of the rag, usage of the rag in the Guru Granth Sahib, historical dimensions of the rag, nature of rag, the musical form of a rag, aroh, avroh, vadi, etc. |
| Poetical Dimension | The Guru Granth Sahib is Divine-revelation. Its poetic beauty is also diverse and immeasurable, transcending established norms of literary poetics; it is beyond human capacity to describe it fully. Still, known standards of poetics are utilized, hinting at poetic aspects of the Banis. Attempts have been made to provide a brief overview of figures of speech, poetic forms, and the elements of stylistics used in a salok/pauri. |
| In-text Citations | Provide a summary, clarification, or explanation (where necessary) of the message. |
| Footnotes | Play a versatile role in tagged texts, serving various functions depending on the specific needs of the content. These functions encompass a range of purposes, including but not limited to the following: providing additional or supporting information to expand upon the main text, offering precise definitions of words, terms, phrases, idioms, symbols, or ideas, supplying guidance on the articulation or pronunciation of the text, furnishing contextualization to enhance the interpretation presented in the text (whether historical, cultural, linguistic, literary, or poetic), and citing original references from within the Guru Granth Sahib to reinforce a particular stance or viewpoint. |
Transcription Guidelines
Transcription or transliteration is the practice of representing a written letter or a word from one script to another. It is also the system of rules for that practice. Transcription and transliteration attempt to accurately capture the sound values across writing systems.
Transliteration attempts to be exact. With the help of transliteration, an informed reader should be able to recreate the original spelling of the transliterated words. Transliteration is commonly employed in situations where high precision is required. It is necessary when using words or concepts expressed in a language with a script other than one’s own.
Transcription is slightly different in that it takes into account the sound values represented by the writing systems. Transcription assists in speech and pronunciation rather than the exact written representation. For example:
- ਪਰਮਦਭੁਤੰ ‒ paramadabhutaṅa (transliteration)
- ਪਰਮਦਭੁਤੰ ‒ parmadbhutaṅ (transcription)
- Psychology - ਪਸਯਕੋਲੋਜੀ (transliteration)
- Psychology - ਸਾਈਕੌਲੋਜੀ (transcription)
If relations between letters and sounds are similar in both languages, transliteration may be nearly identical to its transcription. Transcription has a superficial attraction in that it is generally more readable, primarily because it expresses sounds associated with one script using another script.
In regards to Gurmukhi, transcription proves utilitarian because the script is highly phonetic. Because this project concerns the spoken aspects of the script, transcription is utilized throughout this volume. When writing proper nouns outside of the context of line meanings and footnotes, common spellings will be used instead of transcription-accurate spellings.
Ex: Duni Cand → Duni Chand
Shekh Ibrahim → Sheikh Ibrahim
Shekh Ibrahim → Sheikh Ibrahim
Considering that the pronunciation of Guru Granth Sahib is closely related to its interpretation, an accurate and standardized transcription system assumes a very important role since meanings tend to change with even a slight variation in tone or nasalization. An accurate transcription would thus supplement the correct articulation of phones.
Developing a standardized transcription would aid both the Sikh Diaspora and Western scholars who wish to grasp the language of Guru Granth Sahib better. A universally accepted system will go a long way in advancing the language and its understanding. Due to shortcomings in the English language in general, and the Roman script in particular, it has proved challenging to develop a technique for transcription with the capacity to consistently and accurately transfer text from Gurmukhi characters to Roman characters. Numerous attempts have been made in the past, and gratefully, modern linguistic standards and thorough research have finally made Gurmukhi-Roman transcription a reality.
A majority of the characters used to transcribe Gurmukhi into English have been derived from a universally recognized system of linguistics. For those Gurmukhi letters lacking an equivalent representation in the Roman alphabet, a symbol comparable to a character with an associable sound has been generated to represent those alphabets. As each Gurmukhi letter represents a unique audible sound, it has been assigned its own symbol for transcription into the Roman script.
TRANSCRIPTION GUIDELINES
Since speech precedes writing, identifying speech sounds is vital for establishing the correct pronunciation of a word. The sound being produced while uttering a word is more important than the rules in establishing the correct transcription output. Hence, the pronunciation precedes the transcription rules. Transcription rules only help in understanding and establishing commonly identifiable patterns.
| C1 | C2 | C3 | C4 | C5 | |
|---|---|---|---|---|---|
| R1 | Vowels | ਸ (s) | ਹ (h) | ||
| ੳ (-) | ਅ (a) | ੲ (-) | |||
| R2 | ਕ (k) | ਖ (kh) | ਗ (g) | ਘ (gh) | ਙ (ṅ) |
| R3 | ਚ (c) | ਛ (ch) | ਜ (j) | ਝ (jh) | ਞ (ñ) |
| R4 | ਟ (ṭ) | ਠ (ṭh) | ਡ (ḍ) | ਢ (ḍh) | ਣ (ṇ) |
| R5 | ਤ (t) | ਥ (th) | ਦ (d) | ਧ (dh) | ਨ (n) |
| R6 | ਪ (p) | ਫ (ph) | ਬ (b) | ਭ (bh) | ਮ (m) |
| R7 | ਯ (y) | ਰ (r) | ਲ (l) | ਵ (v) | ੜ (ṛ) |
Consonants
- The consonants begin from s (ਸ), and continue through ṛ (ੜ).
- In pronunciation, a consonant that stands independent of a vowel character will be followed by an implicit “a” (muktā).
- a. The above statement is only true for consonants devoid of vowel characters. However, if the consonant is the final letter of the word, then the implicit “a” is omitted in transcription.
Example 1: ਨਦਰ (na + da + ra = nadar)
Example 2: ਸਤ (sa + ta = sat) - The implicit “a” is applicable at the end of a single character word.
Example 1:ਨ (na)
Example 2:ਤ (ta)
- a. The above statement is only true for consonants devoid of vowel characters. However, if the consonant is the final letter of the word, then the implicit “a” is omitted in transcription.
- There are instances where the implicit “a” is overlooked. In these cases, the “a” can be omitted as it aids in pronunciation. The inclusion of the implicit “a” is not inaccurate, but more functional.
Example 1:ਦਰਸਨ (da + ra + sa + na = darsan)
Example 2:ਕਰਤਾ (ka + ra + tā = kartā) - When a consonant with a short “a” is followed by a vowel character supported by a vowel base (specifically ਉ and ਇ), then the vowel symbol will be indicated by a corresponding dieresis (ï or ü) vowel.
Example 1:ਸਉ (sa + u = saü)
Example 2:ਗਇ (ga + i = gaï)
| VOWELS | ਅ | ਾ | ਿ | ੀ | ੁ | ੂ | ੇ | ੈ | ੋ | ੌ |
|---|---|---|---|---|---|---|---|---|---|---|
| TRANSCRIPTION | a | ā | i | ī | u | ū | e | ai | o | au |
Vowels
- There are three vowel bases (ੳ, ਅ, ੲ).
- In addition to the implicit “a” that follows consonants independent of vowels, there are ten vowel characters (see vowel chart).
- Of the three vowel bases, only ਅ can stand independent of another vowel character.
Example 1:ਅਗਨ (a + ga + na = agan)
Example 2:ਅਕਾਲ (a + kā + la = akāl) - If a vowel character is directly followed by another vowel base and character, then the implicit “a” will be omitted.
Example 1:ਜਾਇ (jā + i = jāi)
Example 2:ਕੀਓ (kī + o = kīo) - If a vowel character combines with a vowel base to produce the first letter in the word, there will be no “a” preceding the vowel.
Example 1:ਊਪਰਹੁ (ū + pa + ra + hu = ūparahu)
Example 2:ਆਸਣੁ (ā + sa + ṇu = āsaṇu) - If a vowel character is present with a consonant rather than a vowel base, then there will be no “a” between the consonant and the vowel.
Example 1:ਸੂਰਾ (sū + rā = sūrā)
Example 2:ਮੋਹਿ (mo + hi = mohi)
ṬIPPĪ (ੰ)
- When a ṭippī is representing one of the five sounds (ṇ, ṅ, ñ, n, m), it will not be followed by an implicit “a.”
Example 1:ਖੰਡ (kha + ṇ + ḍa = khaṇḍ)
Example 2:ਚੰਗਾ (ca + ṅ + gā = caṅgā) - If a ṭippī is representing one of the five sounds (ṇ, ṅ, ñ, n, m), and the letter following the ṭippī falls within rows 2-6 (consonant chart), then the ṭippī will make the sound of the last letter in the corresponding row.
Example 1:ਅੰਤ (a + n + ta = ant)
Example 2:ਸੰਗਤਿ (sa + ṅ + ga + ti = saṅgati)- If a letter following the ṭippī falls in row 1 or 7 (consonant chart), then the ṭippī predominantly makes a “n” sound (consonant nasalization) and occasionally a “ṁ” sound (vowel nasalization).
Example 1:ਸੰਸਾ (sa + n + sā = sansā)
Example 2:ਮੁੰਲਾ (mu + ṁ + lā = muṁlā) - When a ṭippī represents one of the five sounds (ṇ, ṅ, ñ, n, m), and the letter emphasized by the ṭippī represents the same sound (ṇ, ṅ, ñ, n, m), then it will create a double sound (compound), and should be transcribed accordingly.
Example 1:ਅੰਮ੍ਰਿਤ (a + mma + ri + ta = ammrit)
Example 2:ਮੰਨੀਐ (ma + nnī + ai = mannīai)
- If a letter following the ṭippī falls in row 1 or 7 (consonant chart), then the ṭippī predominantly makes a “n” sound (consonant nasalization) and occasionally a “ṁ” sound (vowel nasalization).
- If a ṭippī is at the end of the word, and therefore unsupported by another consonant, then the default sound is “aṅ.”
Example 1:ਸੈਭੰ (sai + bhaṅ = saibhaṅ)
Example 2: ਕਰਮੰ (ka + ra + maṅ = karmaṅ)- If a ṭippī concludes a term in a compound word, then the ṭippī will create the “ṅ” sound.
Example 1:ਅਹੰਕਾਰ (a + ha + ṅ + kā + ra = ahaṅkār)
Example 2: ਅਹੰਬੁਧਿ (a + ha + ṅ + bu + dhi = ahaṅbudhi)
- If a ṭippī concludes a term in a compound word, then the ṭippī will create the “ṅ” sound.
- All vowel nasalization are denoted by “ṁ.”
Example:ਤੂੰ (tū + ṁ = tūṁ) - The ṭippī has two possible connotations. It commonly symbolizes an additional sound incorporating one of five characters (ṇ, ṅ, ñ, n, m), and sometimes denotes a nasalization (ṁ). Identification of correct usage in various instances can only be determined with the knowledge of the language.
BINDĪ (ਂ)
- The bindī can play two different roles. Predominantly, it calls for vowel nasalization (and in a few instances, consonant nasalization) that produces a “ṁ” sound. It occasionally forms a “n” sound. One can know the role of bindī only with an understanding of the language.
- When creating a “n” sound, there will be no implicit “a” sound following the “n” sound.
Example:ਸਾਂਤਿ (sā + ṁ + ti = sāṁti) - All vowel nasalizations are denoted by “ṁ.”
Example 1:ਤੂਹੈਂ (tū + ha + aiṁ = tūhaiṁ)
Example 2:ਹਾਂ (ha + āṁ = hāṁ)
VISARG ( ਃ)
- The Visarg is represented by a “ḥ.” It is pronounced as a softer “h,” and an implicit “a” precedes the “ḥ.”
Example 1:ਦ੍ਰਿੜੰਤਣਃ (dri + ṛa + n + ta + ṇa + ḥa = driṛantaṇaḥ)
Example 2:ਲਿਖੵਣਃ (li + kha + ya + ṇa + ḥa = likhyaṇaḥ)
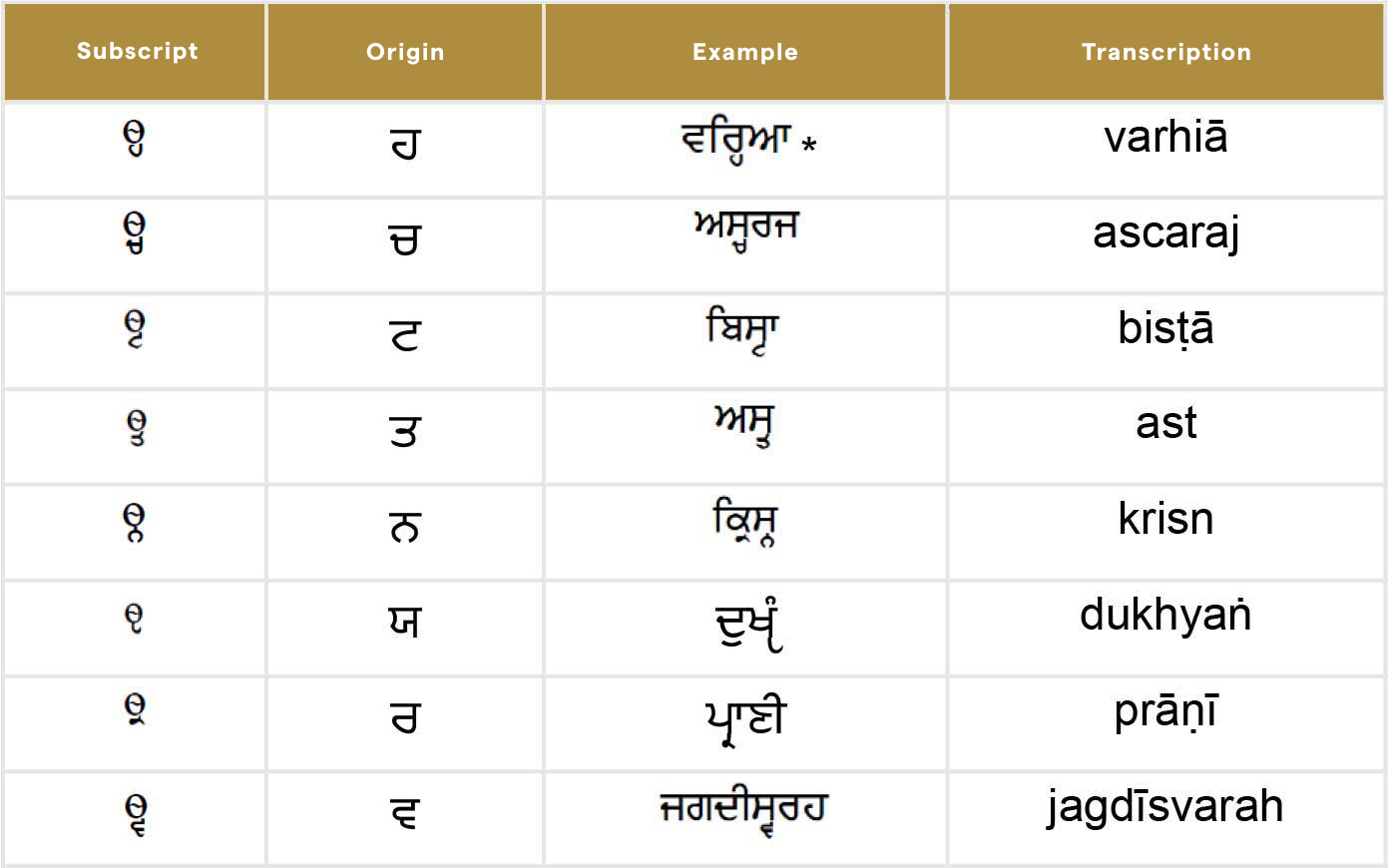
SUBSCRIPTS
- There are eight subscripts used within Guru Granth Sahib.
- The subscript appears below the consonant.
- The subscript is pronounced directly after the consonant above it; there is no implicit “a” between the two.
Example 1: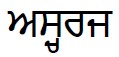 (ascaraj)
(ascaraj)
Example 2: (dastagīrī)
(dastagīrī) - If a vowel supports a consonant and the subscript, then the subscript will follow the consonant but precede the vowel in pronunciation.
Example 1: (bisṭā)
(bisṭā)
Example 2: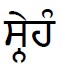 (snehaṅ)
(snehaṅ)
HALANT-LIKE SYMBOL (ੑ )
- Appearance of this symbol in Guru Granth Sahib is represented through the same in the Roman script as well.
Example 1:ਜਿਨੑੀ (ji + n̖ī = jin̖ī)
Example 2:ਧਿਆਵਨਿੑ (dhi + ā + va + n̖i = dhiāvan̖i)
PROLONGATION (ਅ)
- When appearing at the end of a word and directly following a vowel character, the A represents a prolongation of the sound preceding it.
Example 1:ਜੀਅ (jī + a = jīa)
Example 2:ਲੋਅ (lo + a = loa)
Cardinal Numbers
| Roman | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| Gurmukhi | ੦ | ੧ | ੨ | ੩ | ੪ | ੫ | ੬ | ੭ | ੮ | ੯ |
NUMERALS
- Gurmukhi numerals are transcribed through the respective Roman digits as per the table above. However, a number may be properly spelt in the transcription if the original in the Gurmukhi script indicates so.
Example 1: ੧ (1)
Example 2:ਇਕੁ (i + ku = iku)
ADOPTIONS
- Farsi
- If an equivalent sound for a Farsi inspired letter exists in the Roman script, then that Roman letter is used in the transcription.
Example 1:ਫ਼ (f)
Example 2:ਜ਼ (z) - If there is no corresponding sound already inscribed in the Roman alphabet, then the sound will be indicated with a line underneath the corresponding Roman letters.
Example 1: ਗ਼ (gh)
Example 2: ਖ਼ (kh) - The contemporary version of the Gurmukhi script has adopted five new sounds that are indicated with a dot under the corresponding Gurmukhi letter: ਗ਼ (gh), ਜ਼ (z), ਫ਼ (f), ਖ਼ (kh), ਸ਼ (sh).
- Beside these five, the Gurmukhi script has later adopted another sound represented by ਲ਼ (ḷ).
- If an equivalent sound for a Farsi inspired letter exists in the Roman script, then that Roman letter is used in the transcription.
- Adhak (ੱ )
- The adhak conveys which syllable should be stressed. Though used within secondary writings of the Sikhs, the adhak came into use after the Guru Granth Sahib was compiled. Therefore, it does not appear within the text of the Guru Granth Sahib.
- Gurmukhi characters emphasized by the adhak will be written twice in the Roman script.
Example:ਵਡਮੁੱਲਾ (va + ḍa + mu + llā = vaḍmullā) - If more than one Roman alphabet is utilized to represent a Gurmukhi letter that is emphasized by the adhak, then only the first letter will be doubled.
Example:ਭੱਠੀ (bha + ṭṭhī = bhaṭṭhī)






